Web
Copy (WCP)
----- A Web document copy/distributing
Tool
Ruigang
Yang
Department of Computer Science
Columbia University, New York
ryang@cs.columbia.edu
Over the last decade, the World-Wide Web has becoming the largest information database in the world. Almost every kind of information we can possibly imagine can be found some where in the web. With the introduction of Hyper Text Markup Language (HTML), navigating in the web becomes easy and less confusing, because information are organized by these links between relevant pages. However, since the links between webpages can be arbitrary, copying/moving a compound document which consists multiple pages become a non-trivial problem in the World-Wide Web society. Even the leading web brower can not guarantee to save a complete page without broken links. So here, we proposed a software to copy/move/distribute compound document in the web, we call it Web Copy (WCP).
2. Requirement Analysis and Function Specification (Back to Top)
Before we go on, we first define some terms we will use through out this proposal. A page means a single HTML file specified by a single URL or a directory path. A set of inter-related pages constitutes a document. The goal of WCP is to provide the function to copy/move/distribute documents on the world-wide web.
2.1 Collecting A Document (Back to Top)
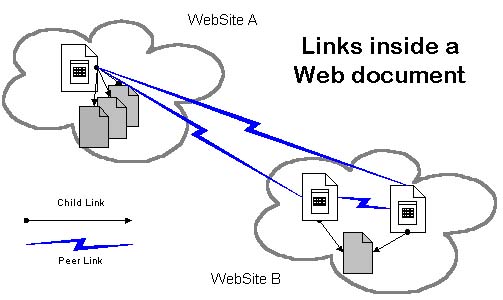
A page usually contains links to other distinct pages, unlike the tree directory structure in most file system, these links usually form a complex network which conceptually form a compound document. These links can be roughly divided in to 2 categories, 1) Child link, which points to a component of this page itself, embedded images and/or audio files are child links. 2) Peer link, which point to other page, together with which conceptually constitute a single compound document. A example of such peer link is the links of the index page of most on-line manuals. It might be a little confusing to consider a index page contains peer links , rather than child link to the contents which are indexed. But if we consider a book, the relationship of index pages and chapters are peer to peer. Their parent is the entity -book, which is only a conceptual in the hyper world, because no single page can stand for a book (unless this page contains all the content of the book, but copy becomes trivial for such case). So it is correct to define the links between index page and contents page as peers. The next figure gives a scenario what the internal structure of a web document may like like.
For page contains child links, the copy or moving such page requires multiple ftp or http sessions. In Netscape Navigator, its save function only save the HTML file itself, if the page contains any images linked by relative path, the saved copy will display this image as "file not found". The exposed a corner of the complexity involved in the copying of hyper-linked web documents. Compared to pages containing peer links, this problem is relatively easy to solve. Because child links, by their definition, are clearly defined by the HTML syntax. They are not recursive , at most one lever down. By parsing the HTML page, we can retrieve/download all these child links without human intervention.
The real challenge of WCP lies in the processing of the peer links. Due to the distributing nature of the world wide web, the conceptually related pages which form a document may not necessarily aggregated in a same physical location, they may be in a same directory, may be in the same web site, or may be all over the world. For example, an on-line book may be written by several authors from different institutions, each author maintains their own chapters on the web. So the index page of this book contains links to several site over the world. And in every chapter, the author may include links to the reference, the reference may contain reference too, so on and so forth. Thus , the boundary of peer link become vague, i.e. how can the program tell whether one link in the link chain is a internal or external one and to decide to stop or not. If we don’t impose any constraints on WCP’s processing of peer links, we may get a document containing more irrelevant information than the information we are interested in, or in a worst case, the entire Internet itself, without mentioning if we would ever be able to store these information in a single file system. Thus, human interaction is required for WCP. These are a couple of different approaches. On is to define the maximum depth of the recursive search of peer links. This requires the least of human interaction. We can also provide a keyword/directory -based query method. For example, files under the same directory or contains a set of user-defined keywords are considered as parts of the documents. The burden of human interaction for this method is not heavy. But based n the experience with those web search engineers, keyword search may result in a substantial growth of pages which are totally irrelevant to the topic of interest. We may also provide a list of links for every page, let the user decide which link should be followed, which should be stopped. This involves the most of human interaction, the benefit is the exact amount of information user wants, no more, no less. WCP shall provide all the 3 methods described above.
2.2 Saving/Distributing A Document (Back to Top)
Once we have all the pages of a document, it is desirable to store them under a single directory. If the page are from different sites, it is necessary to modify the HTML files to preserver the integrity of links.
Some time, we want to send the document to a group of people or upload it to a local server. WCP shall provide a consistent interface so the compound document can be distributed easily according to user’s requirement. So the saving process may be different according to the destination of the document. It may be a local operation of the file system, may be sent by mail, or may be posted to a web server using the http server’s upload supports. All these operation shall be transparent to user. WCP shall be expandable with respect to distribution process. A usable interface is desirable so new standard of electronic media exchange can be incorporated into the system seamlessly.
It may be useful to add an annotation component to WCP. User can add some comments to the original document. With respect to copyright law, WCP may need to add a couple of lines to identify the document from its original copy. But WCP should not be a HTML authoring tool. There are already a lot powerful tools to complete this function.
2.3 Misc. Function (Back to Top)
Because some user interaction is expected during the operation of WCP, A graphical user interface necessary. It shall provide the status of copy, user options, on-line help, etc.
With the rapid growth of dynamic page technology , i.e. page generated on the fly ( usually by a CGI script) and the versatility of custom-define MIME type embedded in the page, WCP shall take these into account in the design phase. MIME type support is a particular complicated problem and there seems no easy solution to this. Every type is handled differently by different browser on different platform. For example, Netscape Navigator supports these MIME type by plug-ins, most of which are developed by third parties. It is desirable to set up a central database of these plugins. If a page contains some MIME types and the user's brower is unable to handle them, WCP shall contact the database (possibly a web site) to know where these plugins can be downloaded. Of course, the central database needs to be updated routinely, but this is beyond the scope of this proposal.
3. WCP Architecture (Back to Top)
According to the requirement analysis, WCP can be decomposed to several components as illustrated in the following figure.
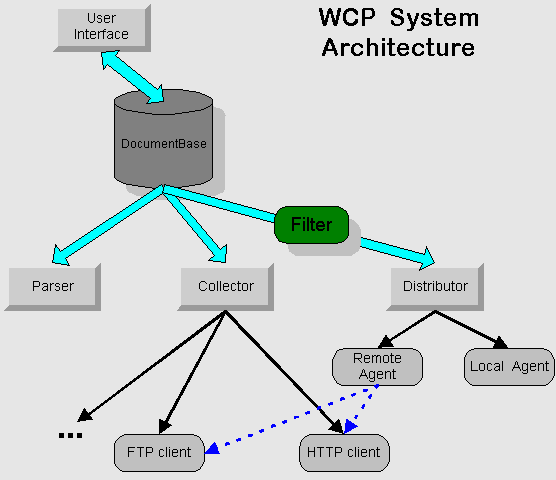
 is the central repository
where all the tempoary file during the copying process shall be indexed.
Because it is common that 2 page will refer to each other, forming a loop
link, the DocumentBase shall have the intelligence
to tell if a page has already been stored or not. So no duplicate copies
of a same page will exist in the database. This first preserves the integrity
of the database, second, will improve the efficiency of copying. It shall
be implemented as a Hash table indexed by the complete URL of the page.
is the central repository
where all the tempoary file during the copying process shall be indexed.
Because it is common that 2 page will refer to each other, forming a loop
link, the DocumentBase shall have the intelligence
to tell if a page has already been stored or not. So no duplicate copies
of a same page will exist in the database. This first preserves the integrity
of the database, second, will improve the efficiency of copying. It shall
be implemented as a Hash table indexed by the complete URL of the page.
![]() provides a user friendly
graphical interface. User shall be able to use the 3 retrieve methods described
in Section 2.1, independently or combinationally. An on-line help system
will be help. During the download process, the interface shall provide a
status bar indicating the process of copy, etc.
provides a user friendly
graphical interface. User shall be able to use the 3 retrieve methods described
in Section 2.1, independently or combinationally. An on-line help system
will be help. During the download process, the interface shall provide a
status bar indicating the process of copy, etc.
![]() parse the input
HTML page to pick all the links in it. The HTML tags it shall recognize include,
but not limited to HREF, IMG, SRC. It returns a list of links to the
DocumentBase.
DocumentBase filter out the links which already
exist, then pass the list to Collector.
parse the input
HTML page to pick all the links in it. The HTML tags it shall recognize include,
but not limited to HREF, IMG, SRC. It returns a list of links to the
DocumentBase.
DocumentBase filter out the links which already
exist, then pass the list to Collector.
![]() is a set of protocol
clients which can talk to remote host/server using the appropriate protocol
to retrieve document. At least HTTP and FTP client should be implemented
in the prototype. In future extensions, new client may be added, such as
the SQL client, POP client. Because these protocol clients are encapsulated
inside the Collector component, WCP can incorporate
new protocol seamlessly.
is a set of protocol
clients which can talk to remote host/server using the appropriate protocol
to retrieve document. At least HTTP and FTP client should be implemented
in the prototype. In future extensions, new client may be added, such as
the SQL client, POP client. Because these protocol clients are encapsulated
inside the Collector component, WCP can incorporate
new protocol seamlessly.
![]() save/distribute
downloaded document to one or multiple destination. It contains 2 agents,
local and remote. Local agent handle the normal local file system
operations. Remote agent is able to send the document to a remote destination,
or upload to the server. The remote agent may use some of the protocol clients
to send/upload document. So the protocol clients are shared by
Collector and
Distributor.
save/distribute
downloaded document to one or multiple destination. It contains 2 agents,
local and remote. Local agent handle the normal local file system
operations. Remote agent is able to send the document to a remote destination,
or upload to the server. The remote agent may use some of the protocol clients
to send/upload document. So the protocol clients are shared by
Collector and
Distributor.
![]() modify the document
if necessary. Annotation, repackage (change the directory structure), Format
converter (GIF to JPEG, HTML to text, HTML to ps, etc.) will be implemented
inside this component.
modify the document
if necessary. Annotation, repackage (change the directory structure), Format
converter (GIF to JPEG, HTML to text, HTML to ps, etc.) will be implemented
inside this component.
WCP will be implemented using Java. We choose Java because
Task |
ETA |
| Submit requirements analysis and functional specification document | Oct.10 |
| Submit design document | Oct. 20 |
| Complete coding | Nov .10 |
| Complete testing | Nov. 20 |
| Perform formal demonstration | Dec. 1 |
| Submit working source code and executable | Dec. 10 |
In this proposal, we outlined the framework of WCP, a web crawler utility to that detects, repackages and supports copying of compound documents. The architecture of WCP makes it flexible, extensible and scalable. It can be a personal tool. Yet with the prolification of protocol clients, it can be an enterprise-level tool serving the need of thousands people to get the information from various source all over the web. In the next 2 month, we expect to implement a working prototype of WCP using Java. We will use it to further test our design.